Okay, first of all, I know that coding projects are not fun to read about or look at. Especially when I put them on Facebook in a picture format. But, I wanted to make this, so here it is. In better news, there is only one more programming project on my list.
And that is one of the best things about making. This week I saw yet another web portal clickbait title with the word “BRUTAL” in it. Serbian media loves that word. They use it for literally anything and everything. BRUTAL argument, BRUTAL insult, BRUTAL cleavage…
And because of that, I hate it. It is so misused and overly used and it’s just clickbait. And it actually prolongs this culture around this word and a way of expression. Serbian politicians use it a lot, and their way of expression is just awful. But since they’re in media all the time, society picks up that too. And it’s just all-around negative energy.
So, to get to the point, I was curious how often this word is actually used in media. I know I see it a lot, but I wanted to quantify it. And the best way I know how to is web scraping.
What are web scrapers?
Web scrapers are programs used to extract content and data from websites. The great thing about them is that you can customize them to do whatever you want. You do need some basic programming knowledge and familiarity with HTML and CSS. With those couple of things and some tutorials, you can easily do some basic inquires.
What are the results?
Because of various circumstances, I had only 4-5 hours to work on this so my research isn’t very thorough. I’ve scraped only one website and 6090 articles from 4 categories. Still, this does give some interesting results.
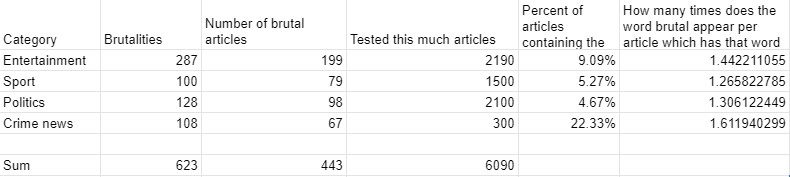
As expected, the biggest percentage of 22% of articles that contain the word brutal is in the Crime news category. And that is actually the only appropriate use of this word. Even though in these cases it is mostly used as clickbait as shock value. Here it is mostly used in the context – brutal beating, brutal murder, brutal torture…
The next biggest percentage is in the Entertainment category. In nearly 10% of the 2190 articles I’ve scraped, we have the word brutal. Which is not really expected if you think about the meaning of this word. Yes, sometimes in slang words that have negative meaning can be used as positive adjectives, but I find it so weird with this word. The word that has synonyms like bloodthirsty, savage, vicious, ferocious, ruthless… And I probably wouldn’t mind it if it was just occasional use, but it is so overused, almost 10% of articles in this category. In this category, it is mostly used in the context – brutal body, brutal dress, brutal insult…
And after that Sport and Politics share a similar percentage of around 5%. You could understand if it was sometimes used in sport, a brutal foul, brutal injury, or something like that. But what does this word have to do with politics? It is used like brutal insult, brutal response, brutal (verbal) attack… How can you respond to someone brutally? By the power of clickbait!
Since I scraped only one website, I chose the Mondo web portal which isn’t a total trash tabloid, but they’re also not a really reputable news source. It would be interesting to do this research more thoroughly, to use more websites, to scrape more articles, to include more variables. For example, to see the distribution over time, the context in which it is used, to compare trashy websites to more reputable ones. Also what interests me is how much did this word get into the general population.
Even though there are many questions I still have, I did get an answer to the original one.

Boring stuff
As always, I used a combination of tutorials, google searches, and previous knowledge when making this. My first thought was to use Selenium because I have some experience with it, but after a quick google search, I found a tutorial that has a lot of similarities with my project so I decided to use BeautifulSoup (Python library for pulling data out of HTML and XML).
If you want to see the full process in detail, I highly recommend the aforementioned tutorial, it is very well written and everything is thoroughly explained. I will just run through my process and some main things I’ve encountered.
First, you need to install Python and a couple of dependencies.
! pip install beautifulsoup4
! pip install requests
! pip install urllibOn top of the file, we import the libraries which we will be using. After that, we set up the global variables which in this case are mostly counters for what we want and the list of the links we want to scrape. These link lists could’ve been automated but since there weren’t a lot of them I pulled them out manually because it was faster that way and I could more easily control batching (which could’ve been automated too, but with the time I had it wasn’t a priority). This is the first part where we can’t give general directions because every website is structured differently and you need to fit your script to it. These links were mostly in a format website/category/subcategory?&page=page_number.
import urllib.request,sys,time
from bs4 import BeautifulSoup
import requests
import re
pagesToGet= 10
brutalno = []
brutal_no = 0 #yes, this variable and the previous one are named like they are because I thought it was funny, it is not the greatest programming practice
brutal_articles = 0
tested_articles = 0
all_urls = ['https://mondo.rs/Zabava/Zvezde-i-tracevi?&page=','https://mondo.rs/Zadruga?&page=']After that comes the part that is the most different from the tutorial because it didn’t have any way to navigate through the pages. I solved this problem by scraping all of the links from the page and then visiting all of them through the for loop.
for link in main_soup.findAll('a', attrs={'class': 'title-wrapper','href': re.compile("^https://")}):
links.append(link.get('href'))
for link in links:
article=requests.get(link)The next step is parsing the text which I handled with BeautifulSoup and the most basic RegEx. This is a second part where you have to adjust your script to your specific case and where you need to know some basic HTML and CSS. Here I’m finding all the div elements on the page with the class .rte because when I inspected the page, that is what the structure of the page was.
text_content=article_soup.find_all('div',attrs={'class':'rte'}) #finding the content of the article
for tc in text_content:
brutalno=tc.find_all(string=re.compile("(?i)brutal")) #(?i) flag in RegEx means it's case-insensitive and we are searching for the word brutal in the articles
brutal_no+=len(brutalno) #incrementing the total of the uses of the word
if len(brutalno):
has_word = True #setting the flag so we can later increment the number of the articles which contain the wordIn the end, I only printed the numbers. The smarter solution would’ve been to save them to a file, but in my case, that wasn’t really necessary and I didn’t have the time for it anyway. This is a beautiful thing when you’re coding some small tool for yourself. You don’t have to worry about it being very well written or efficient or any of that, as long as it does its job.
print('Number of brutal articles: ', brutal_articles)
print('Number of brutalities: ', brutal_no)
print('Went through this much articles: ', tested_articles)You can see the finished script below. If you have any questions, feel free to contact me. And if you wish to do this research in more detail, please let me know the results.
import urllib.request,sys,time
from bs4 import BeautifulSoup
import requests
import re
pagesToGet= 10
brutalno = []
brutal_no = 0 #yes, this variable and the previous one are named like they are because I thought it was funny
brutal_articles = 0
tested_articles = 0
all_urls = ['https://mondo.rs/Zabava/Zvezde-i-tracevi?&page=','https://mondo.rs/Zadruga?&page=','https://mondo.rs/Zabava/Serije?&page=','https://mondo.rs/Zabava/TV?&page=','https://mondo.rs/Zabava/Film?&page=','https://mondo.rs/Zabava/Muzika?&page=','https://mondo.rs/Zabava/Zanimljivosti?&page=','https://mondo.rs/Zabava/Kultura?&page=']
#all_urls = ['https://mondo.rs/Sport/Fudbal?&page=','https://mondo.rs/Sport/Kosarka?&page=','https://mondo.rs/Sport/Tenis?&page=','https://mondo.rs/Sport/Vaterpolo?&page=','https://mondo.rs/Sport/Ostali-sportovi?&page=']
#all_urls = ['https://mondo.rs/Info/Srbija?&page=','https://mondo.rs/Info/Drustvo?&page=','https://mondo.rs/Info/Beograd?&page=','https://mondo.rs/Info/Crna_hronika?&page=','https://mondo.rs/Info/Svet?&page=','https://mondo.rs/EU/tag17755/1?&page=','https://mondo.rs/Info/Ekonomija?&page=','https://mondo.rs/Info/EX-YU?&page=']
#all_urls = ['https://mondo.rs/Info/Crna-hronika?&page=']
for cat_url in all_urls:
for page in range(1,pagesToGet+1):
print('processing page :', page)
url = cat_url+str(page)
print(url)
#an exception might be thrown, so the code should be in a try-except block
try:
#use the browser to get the url. This is suspicious command that might blow up.
page=requests.get(url) # this might throw an exception if something goes wrong.
except Exception as e: # this describes what to do if an exception is thrown
error_type, error_obj, error_info = sys.exc_info() # get the exception information
print ('ERROR FOR LINK:',url) #print the link that cause the problem
print (error_type, 'Line:', error_info.tb_lineno) #print error info and line that threw the exception
continue #ignore this page. Abandon this and go back.
time.sleep(2)
soup=BeautifulSoup(page.text,'html.parser')
main_soup= soup.find('div', attrs={'class':'left-side'}) #div with the class .left-side is the one where all the articles are
links = []
for link in main_soup.findAll('a', attrs={'class': 'title-wrapper','href': re.compile("^https://")}): #searching for all the links to the articles
links.append(link.get('href'))
for link in links:
print('processing link:', link) #I added this so I can see that something is happening in the command prompt
has_word = False
try:
#use the browser to get the url. This is suspicious command that might blow up.
article=requests.get(link)
except Exception as e:
error_type, error_obj, error_info = sys.exc_info()
print ('ERROR FOR LINK:',url)
print (error_type, 'Line:', error_info.tb_lineno)
continue
time.sleep(1)
article_soup=BeautifulSoup(article.text,'html.parser') #making a soup of articles
titles=article_soup.find_all('h1',attrs={'class':'title'}) #finding all the titles in the article
text_content=article_soup.find_all('div',attrs={'class':'rte'}) #finding the content of the article
for tc in text_content:
brutalno=tc.find_all(string=re.compile("(?i)brutal")) #(?i) flag in RegEx means it's case-insensitive and we are searching for the word brutal in the articles
brutal_no+=len(brutalno)
if len(brutalno):
has_word = True
for tt in titles:
brutalno=tt.find_all(string=re.compile("(?i)brutal"))
brutal_no+=len(brutalno)
if len(brutalno):
has_word = True
if has_word: #if the word brutal is contained either in the title or the content we increment the number of brutal articles
brutal_articles += 1
tested_articles += 1
print('Number of brutal articles: ', brutal_articles)
print('Number of brutalities: ', brutal_no)
print('Went through this much articles: ', tested_articles)